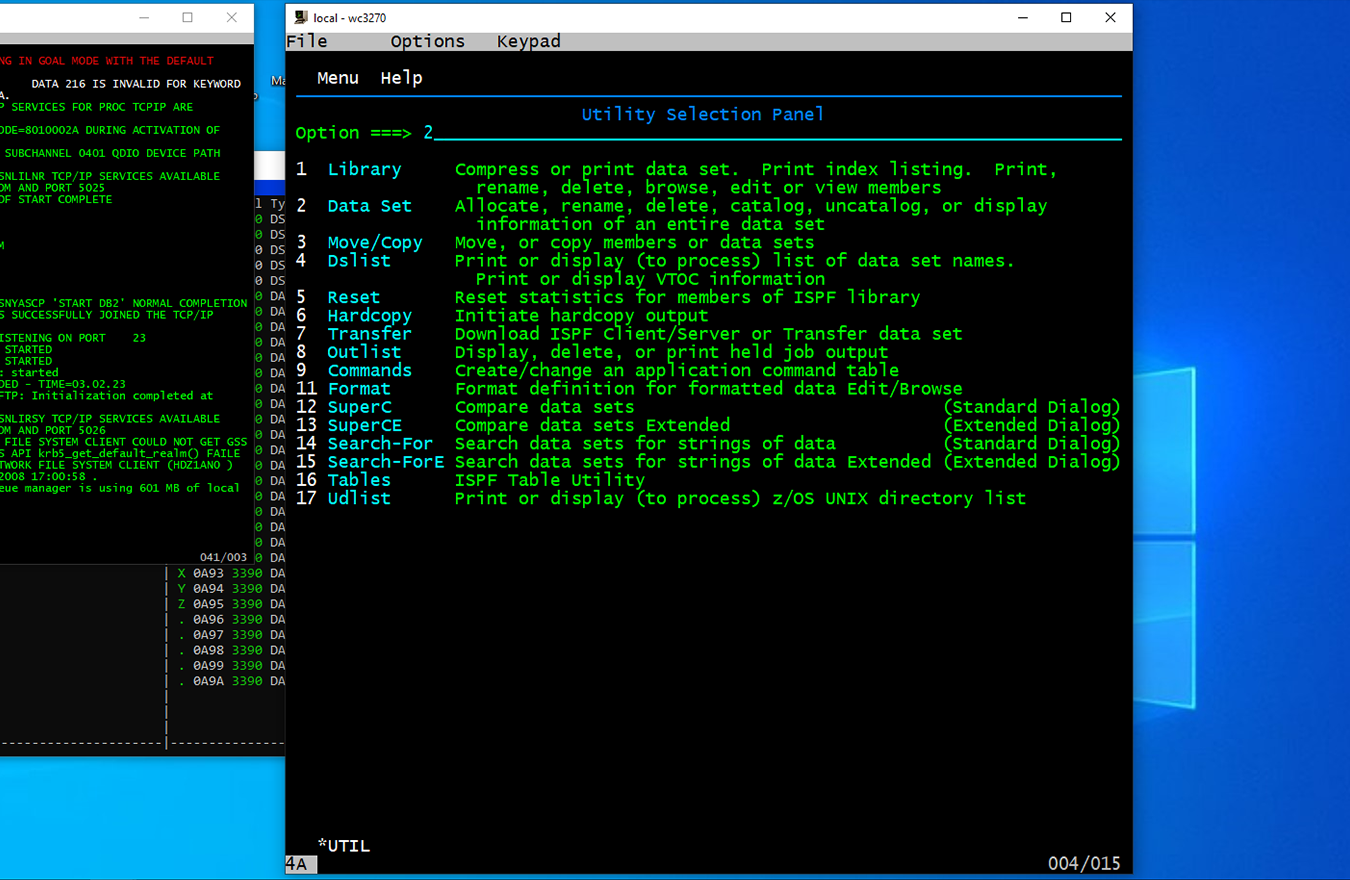
Desde el menú principal de ispf seleccionamos '3 Utilities' (3 y ENTER en la linea de comandos).
En este menú, seleccionamos la opción '2 Data Set' (2 y ENTER en la linea de comandos).
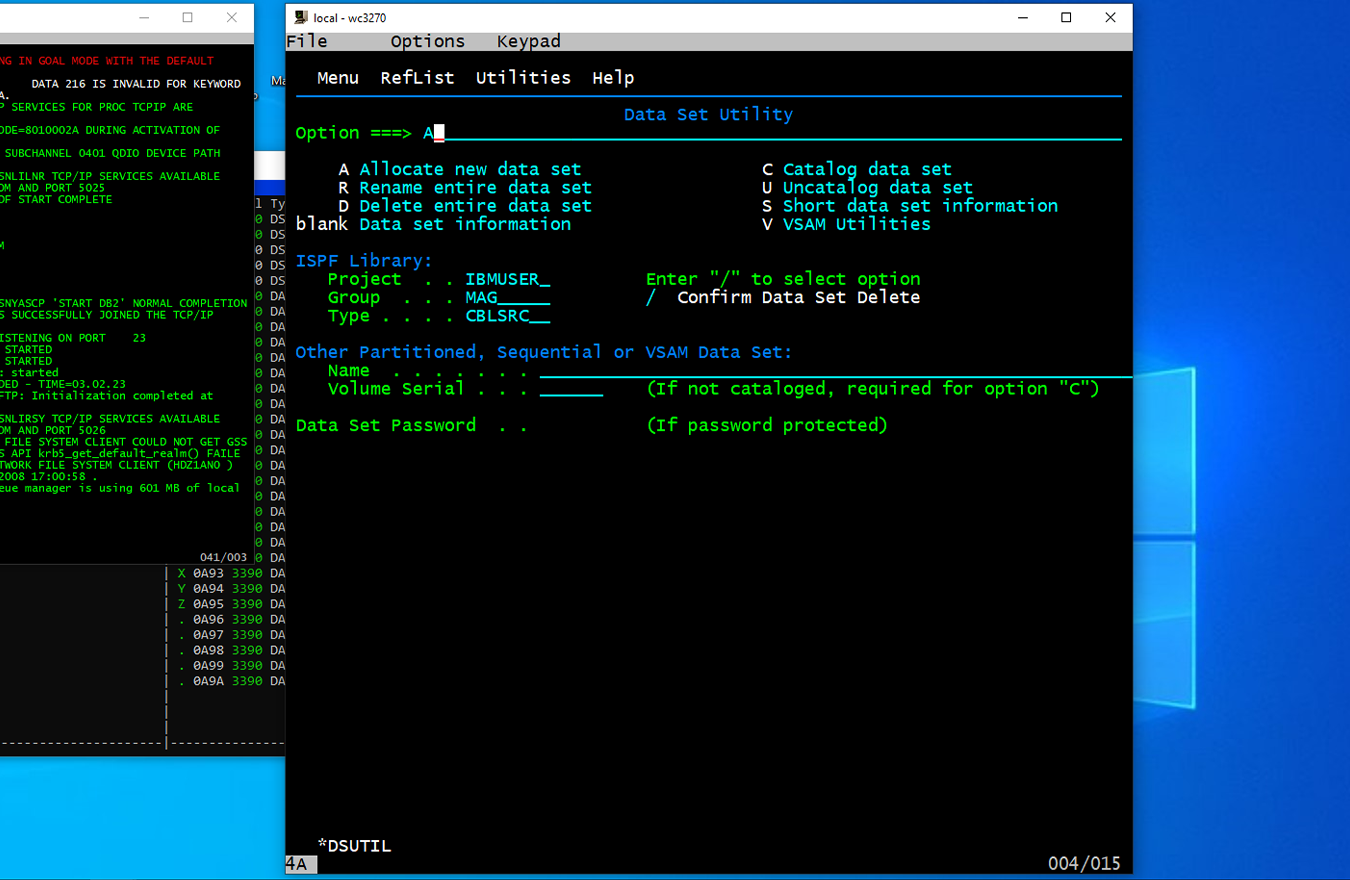
Ingresamos los nombres que vamos a usar en Project, Group, Type.
ISPF Library:
Project . . IBMUSER
Group . . . MAG
Type . . . . CBLSRC
Dentro del tipo CBLSRC pondremos todos los códigos en COBOL sin compilar (FUENTES).
Con la opción 'Option ===> A__________' y ENTER, pasamos a la definición del dataset (arbol de carpetas).
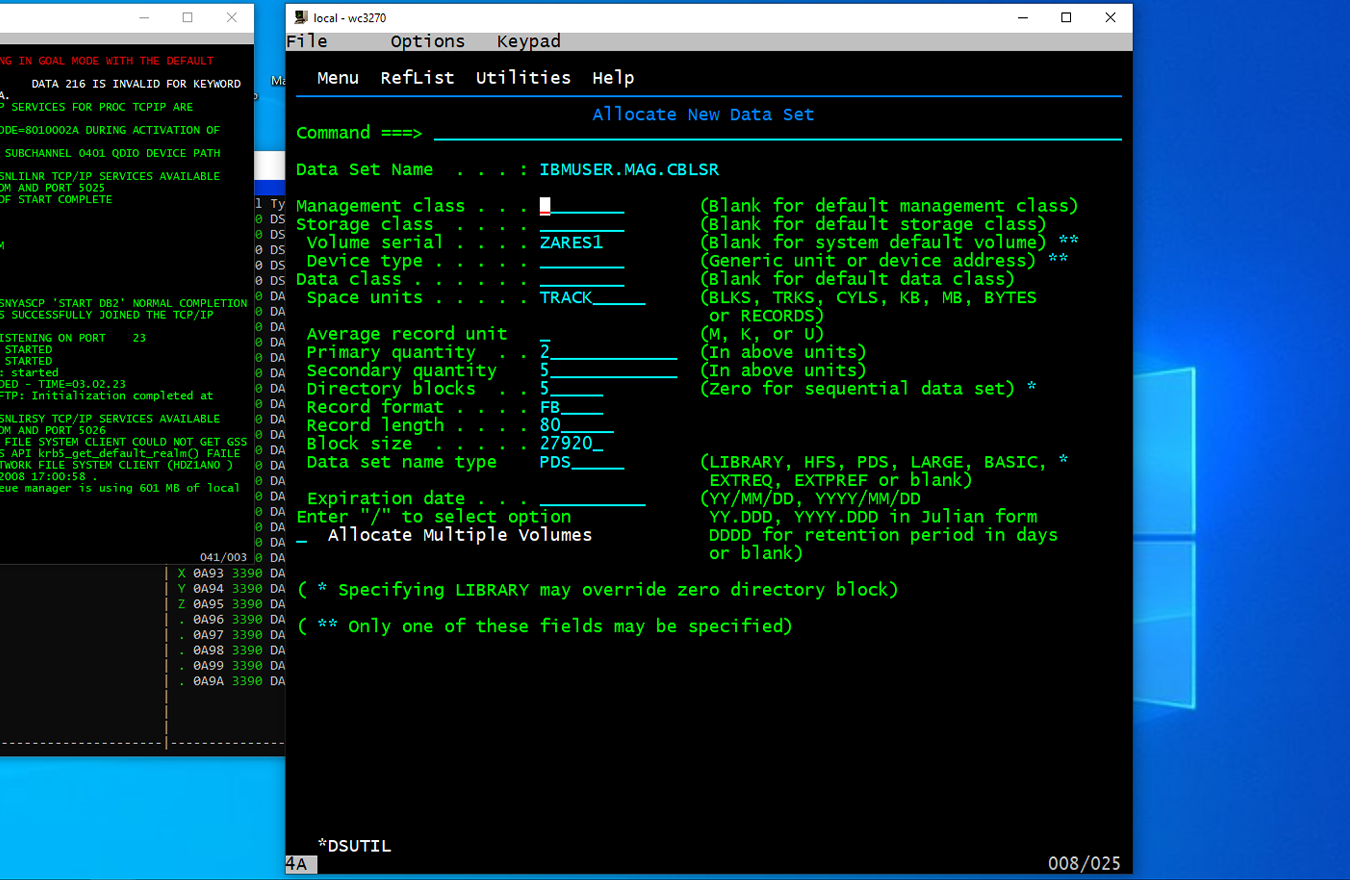
Record length . . . . 80
Block size . . . . . 27920
Verificar siempre que block size sea múltiplo de record length. Record length de 80 significa que los archivos que creemos aquí dentro se guardarán escritos en 80 columnas.
Al apretar ENTER se habra creado el dataset.
Repetimos el procedimiento hasta tener los siguientes datasets:
IBMUSER.MAG.CBLSRC
IBMUSER.MAG.COPY
IBMUSER.MAG.JCL
IBMUSER.MAG.LOAD
IBMUSER.MAG.OBJ
¡Listo!. Terminamos la creación de las carpetas necesarias para poder correr los ejemplos.
NOTA: Los nombres que yo elegí, no es necesario respetarlos, pero todos los ejemplos los usarán y no requerirán cambios los códigos.